Defining Data Models
In Embeddable you define your data models using a data modeling language called Cube (opens in a new tab). You can define your models using YAML or JavaScript syntax. In most cases, YAML is recommended for its simplicity and readability, and that's what we focus on in this guide.
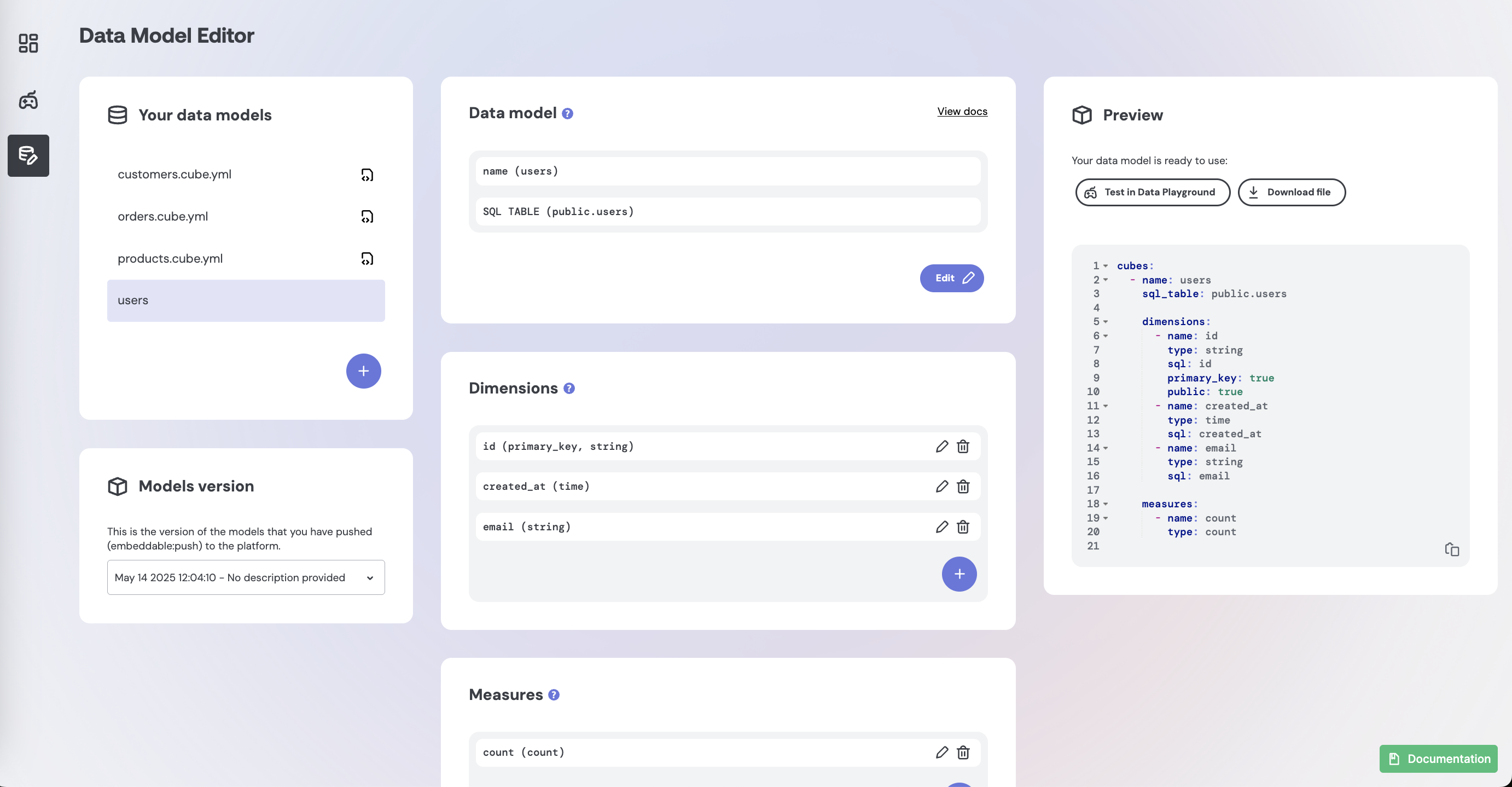
The easiest way to get started is to create your models directly in Embeddable's Data Model Editor:
or you can create the models as files directly in your code repository (learn how).
If you start in the Data Model Editor, you can always export them as YAML to your code repository later.
Whether you're defining your models in the Data Model Editor or directly in code, in the end you're effectively creating a model file that looks something like this:
# src/models/customers.cube.yml
cubes:
- name: customers # A unique identifier
title: My customers # A display-friendly title
data_source: default # The data source connection to use
sql: > # Defines the underlying query
select *
from public.customers
dimensions: # 'dimensions' define fields for filtering or grouping data
- name: id
sql: id
type: number
primary_key: true
- name: email
title: "Email address"
sql: email
type: string
- name: country
title: "Country of origin"
sql: country
type: string
- name: signed_up_at
sql: signed_up_at
type: time
- name: full_name
title: "Full name"
sql: CONCAT(first_name, ' ', last_name)
type: string
measures: # 'measures' define aggregated values (e.g. counts, sums)
- name: count
type: count
title: "# of Customers"
joins: # 'joins' define relationships between this model and others
- name: orders # the name of the data model to join to (not the table)
sql: "{CUBE}.id = {orders}.customer_id"
relationship: one_to_many
Important:
- Embeddable only recognizes files ending in
.cube.ymlor.cube.js. - Each model file begins with the
cubes:keyword. - YAML is sensitive to indentation. Use an online YAML validator like YAML Lint (opens in a new tab) to check your formatting.
- If you use the Data Model Editor, you need not worry about any of this, as the Editor handles that all for you 😎
You can see more data model examples inside your repo (opens in a new tab).
Core Parameters
-
name: A unique identifier for the model (no spaces or special characters).nameis used internally by Embeddable and Cube to reference the model. Updating it once it's in use can potentially break your dashboards. -
title: An optional, human-readable name that appears in the UI. You can change it anytime without impacting the underlying logic. -
data_source: Specifies which data source the model belongs to. This should match the connection name you defined when connecting your database. -
sql_table: Points to the actual table or view in your database (e.g.,public.customers). Use this for straightforward mappings. -
sql: An alternative tosql_tableif you need to define a custom query rather than referencing a single table/view. For example:sql: > SELECT id, name, created_at FROM public.customers WHERE status = 'active'
A common misconception is that you have to write GROUP BY statements in your sql. Instead, use sql to define a base table and then separately define dimensions and measures. The data modeling layer automatically generates the necessary SQL, including GROUP BY clauses, behind the scenes.
-
dimensions: There are all the "virtual columns" that you want to expose in your model (learn more here). -
measures: These are all the "metrics" that you want to be able to calculate from your model (learn more here).
Other Parameters
You can also define other parameters, including joins between models and pre-aggregations to optimize performance.
-
joins: Defines how to link models and handle join relationships. -
description: A short note or summary of what the model represents or how it should be used. Useful for keeping track of intentions or business context. -
pre_aggregations: Optional configurations for creating and managing materialized views or rollups. This helps improve performance by caching common aggregations learn more. Note that pre-aggregations are not currently supported in the Data Model Editor. To use them, please export your data models and add them to your code repository (learn more here). -
views: Views are very useful if you want to create different subsets of your cube models for different use-cases, or if you want fine-grained control of which join path should be used when. Learn more here (opens in a new tab).
These parameters allow you to tailor each data model to match your analytics needs, whether you’re simply mapping a table or performing advanced transformations and aggregations.